 보안 발자국
보안 발자국
[SK shieldus Rookies 16기] 클라우드 기반 스마트 융합보안 과정
클라우드기반 시스템 운영 구축 실무 #06
학습 내용
- SIEM 복습
- Splunk Enterprise 설치
- Search & Reporting
- Splunk 검색 명령어
(12.SIEM_Splunk.pdf + 01.03 필기 p8~로 내용 정리)

원활한 실습을 위해 이번에는 가상환경이 아닌 windows 환경에서 Splunk를 설치하고,
제공되는 튜토리얼 데이터를 이용해 실습을 진행해보았다
Splunk Enterprise 설치
splunk-9.0.1-...x64-release.msi
Splunk Web 실행
설치 마지막에 위처럼 체크를 했다면 자동으로 진입된다
설치 시 설정한 사용자 이름과 암호로 로그인한다
여기에서 Search & Reporting 앱을 이용할 것이다
Search & Reporting
먼저, 수집한 데이터가 없으니 튜토리얼 데이터를 추가해준다
설정 > 데이터 추가


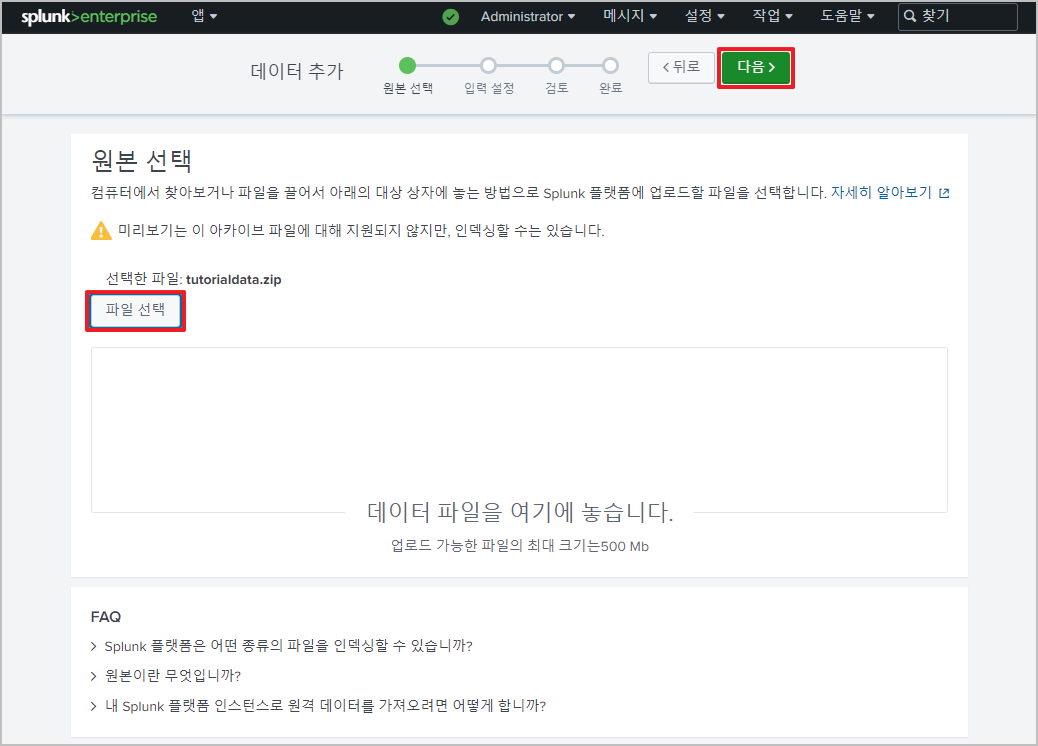


제출 후 업로드 과정에서 정규화, 필터링 작업까지 완료된다.

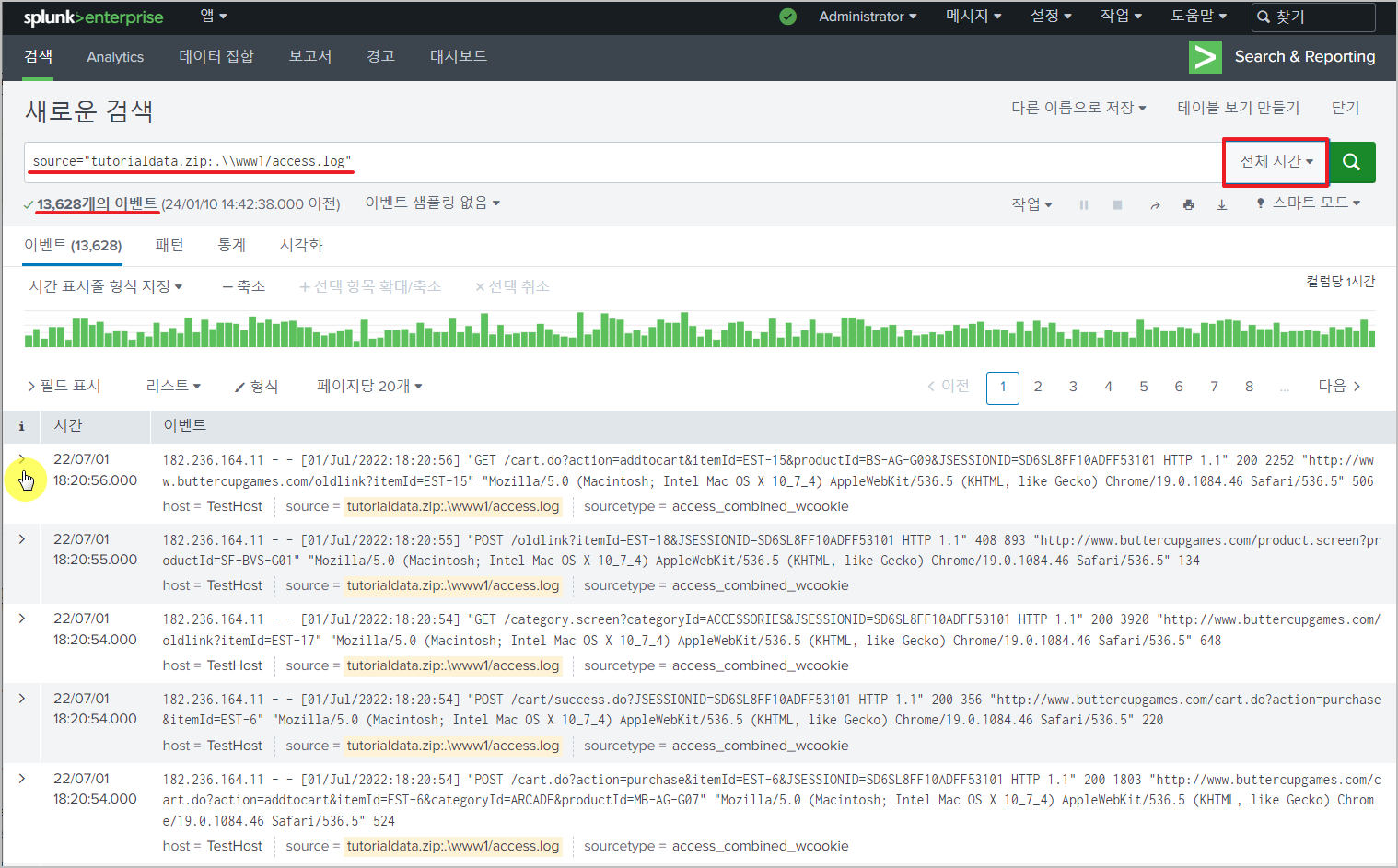
검색 시작을 누르면 다음 화면을 볼 수 있다.



하나를 선택하면, 테이블에 표시하지 않은 필드 포함 전체 정보를 볼 수 있다

업로드했던 로그 zip 파일을 압축 해제해서 봐 보자.
다섯 개 폴더로 이루어져 있다
mailv\secure 로그
로그 날짜 / 시간 / 컴퓨터 이름 / 프로세스id /
: 인증 실패 관련 로그
vendor_sales 로그
vendorID, Code: 상품 이름, 코드 값
AcctID: 계정 ID
www1\access 로그
: 웹 트래픽 로그
www1\secure 로그
: Fail 관련 로그
Splunk 페이지에서 검색 기능을 좀 더 살펴보자.
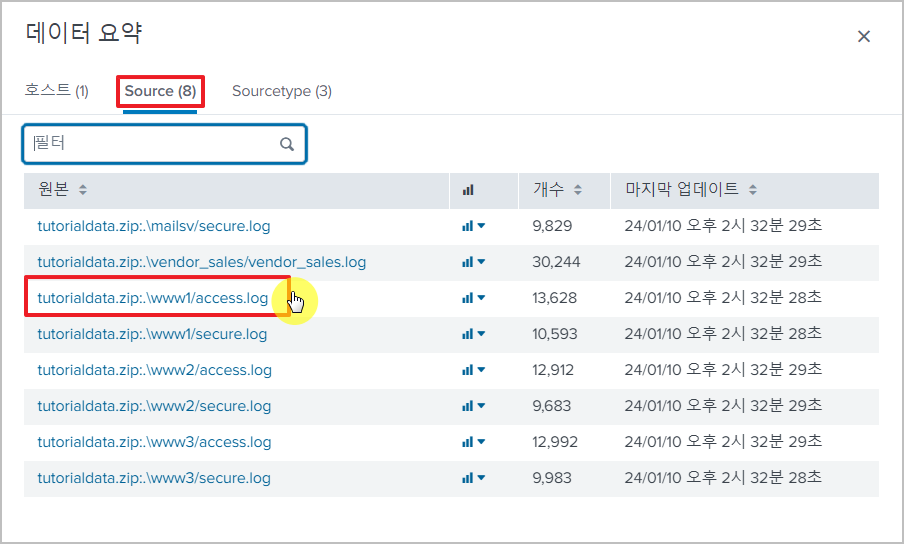
먼저, 왼쪽 상단의 검색 > 데이터 요약을 선택한다

Source > 특정 로그 파일을 선택해서 볼 수 있다

리스트 테이블 오른쪽 필드 목록에서 필드를 선택하면,
해당하는 값에 따른 간단한 분석 결과를 볼 수 있다.
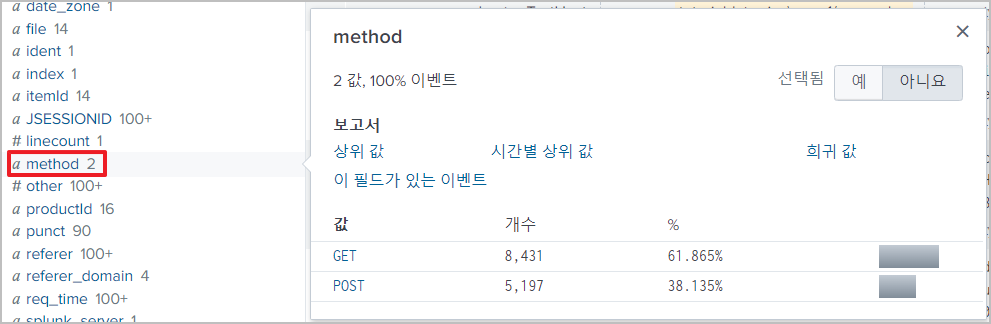
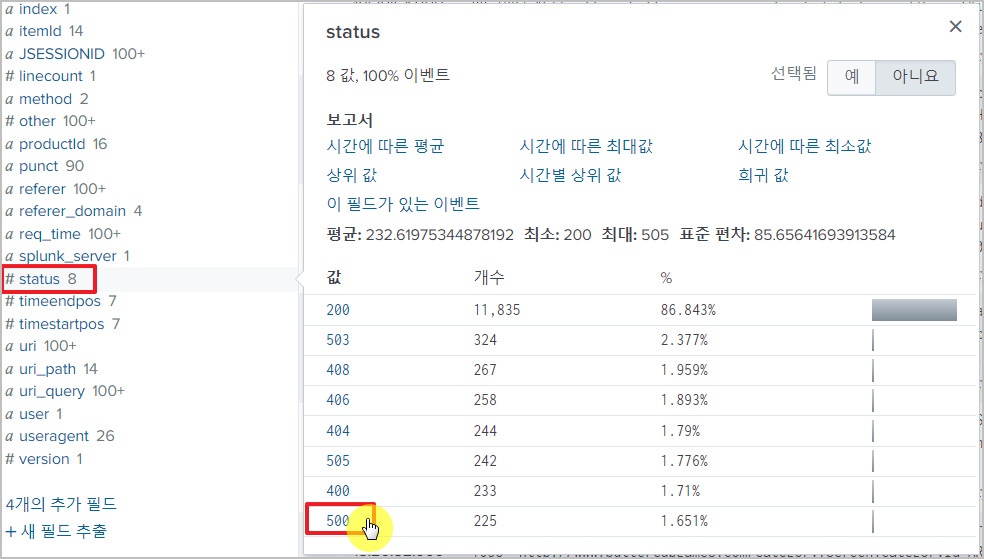
여기에서도 값을 클릭할 수 있고,
클릭하면 검색 조건에 추가되어 결과를 보여준다.
아래 결과에서 막대 그래프를 클릭하면, 해당 날짜의 이벤트만 보이게 된다.
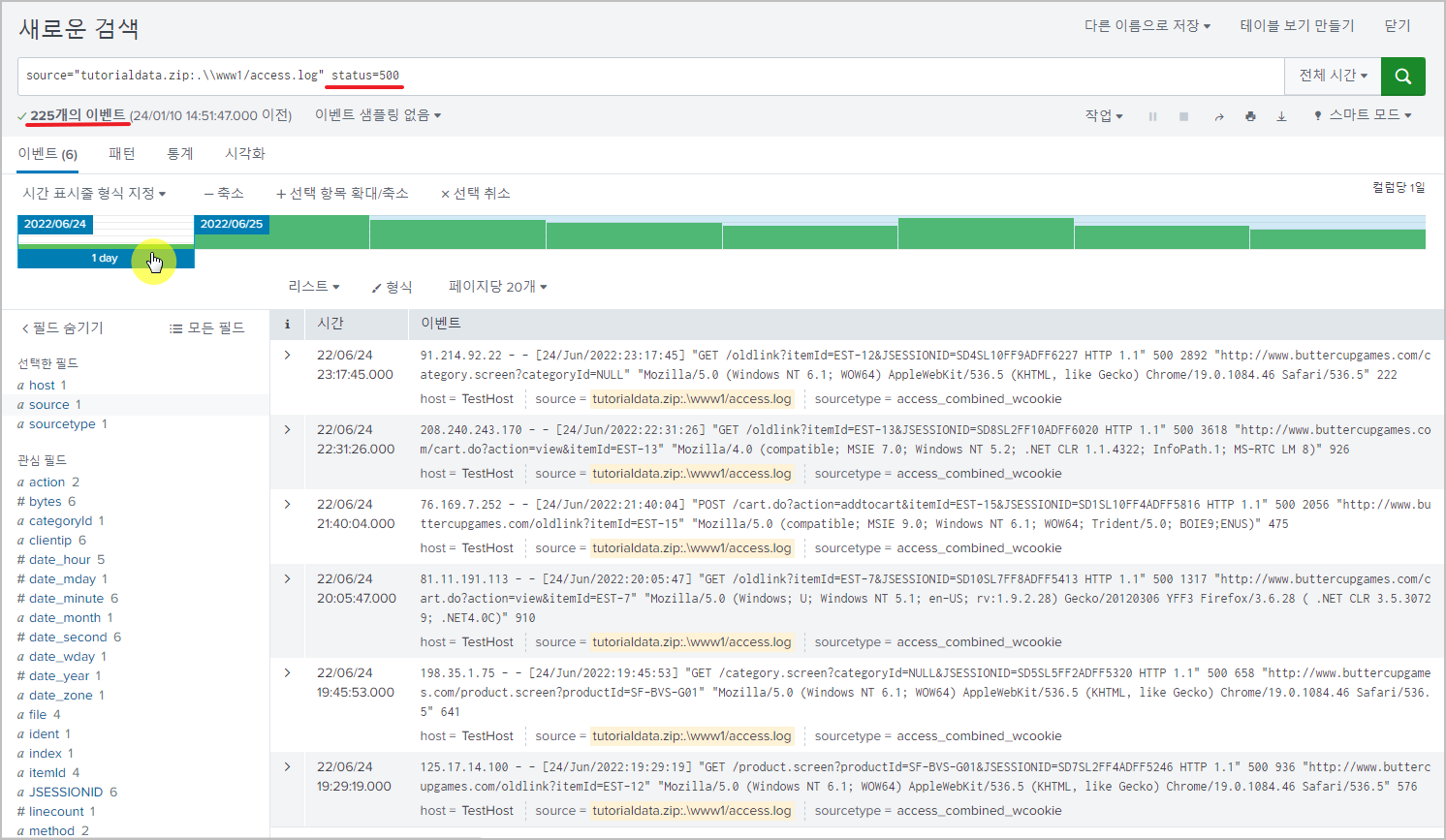
다시 상단의 검색 > 검색 내역을 보면, 지금까지 검색한 필터 목록을 볼 수 있고
검색에 추가하여 다시 검색할 수 있다.

검색 방법
(3:20~)
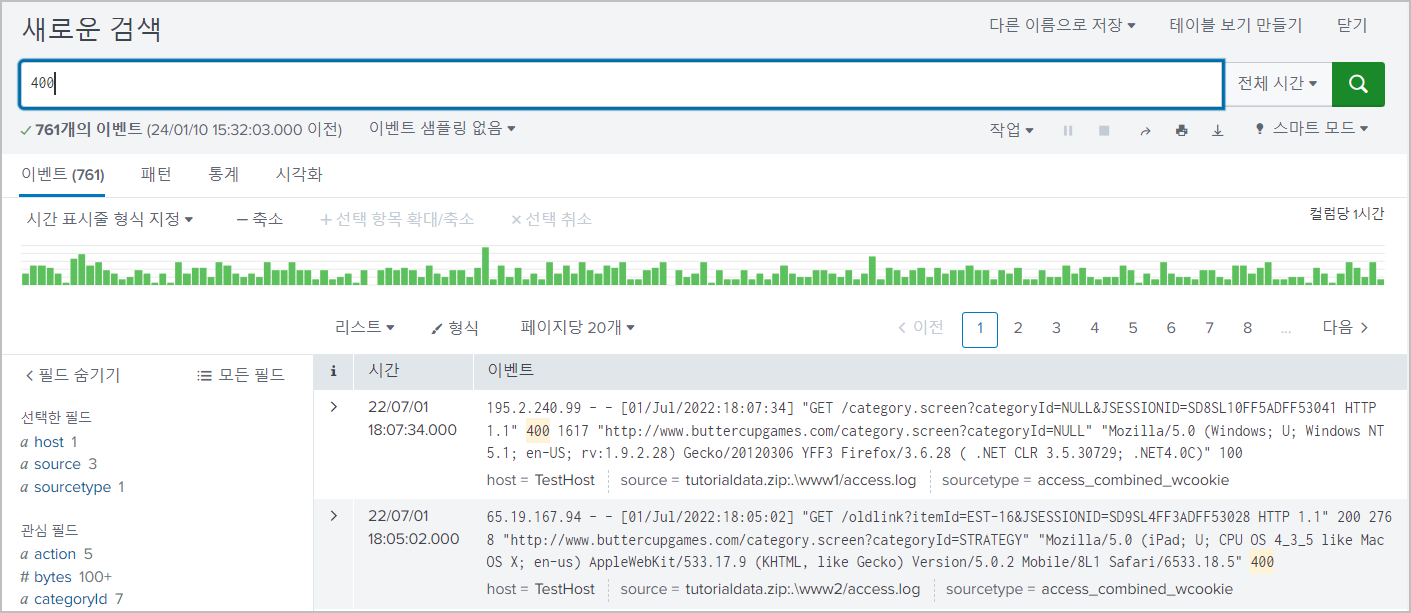
1. 특별한 형식 없이 키워드만으로도 검색 가능하다 (대소문자 구분x)
400
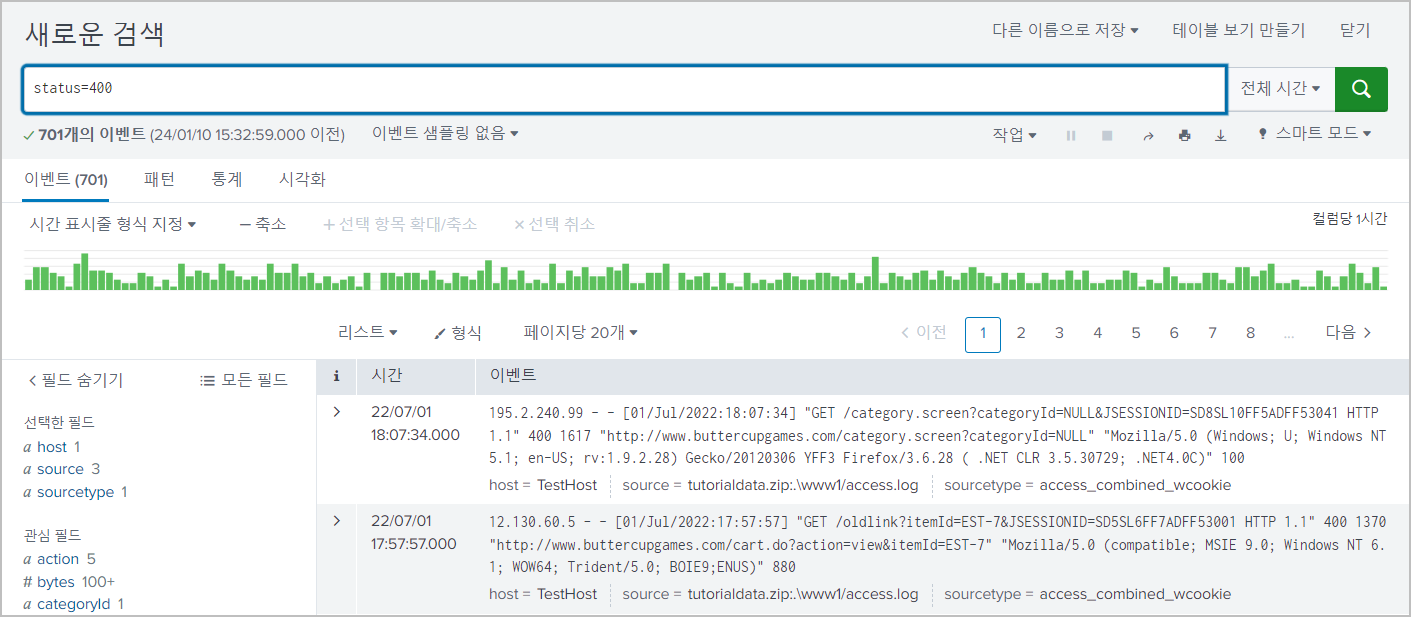
2. 필드명과 필드 값으로 함께 검색하는 것이 더 정확하다
status=400
3. 둘 이상의 조건은 공백으로 구분해 작성하면 되는데,
이 때 둘 사이에 AND 연산이 있는 것과 같다
status=400 categoryId=Null
(status=400 AND categoryId=Null)
4. 공백을 AND가 아닌 한 문장으로 취급하려면 따옴표를 사용한다
"access denied"
5. 다른 연산자를 이용해 검색 가능하다
- OR, NOT
- 대문자로 입력
- 괄호를 이용해 우선순위 지정 가능
401 AND (402 OR 403)
Splunk 검색 명령어
- 데이터 나열, 변환:
- 통계 계산:
- 차트 시각화:
- 비교 분석:
- 다중 문자열과 시간:
table
• 필드명과 결합해 검색 결과를 테이블 형태로 보여줌
• table 명령어 다음에 확인하고 싶은 필드명 적음
• 필드명을 잘못 적으면 행당 필드에 공란이 보임
- 다른 필드에는 값이 보이는데 특정 필드가 공백이면 필드명 입력오류 의심
• 필드명은 대소문자를 구분
• 여러 개의 필드는 쉼표(,) 또는 띄어쓰기로 구분
table <<필드1>> <<필드2>> …<<필드n>>
index=main sourcetype=access_combined_wcookie
| table clientip, method, productId, status
전체 시간 > 검색

rename
• 필드명을 다른 이름으로 변경
• 필드명을 띄어쓰기로 구분하고 싶으면 원하는 필드명을 따옴표로 표시
rename <<원래 필드명>> AS <<변경 필드명>>
index=main sourcetype=access_combined_wcookie
| table clientip, action, productId, status
| rename action AS "Customer Action", productId AS ProductID, status AS "HTTP Status"

sort
• 검색 결과를 정렬
sort (+|-) << 필드명1>>
• 기본 값은 오름차순 정렬
• 내림차순으로 정렬하려면 필드 앞에 마이너스(-)를 붙임
index=main sourcetype=access_combined_wcookie
| table clientip, action, productId, status
| sort action, -productId

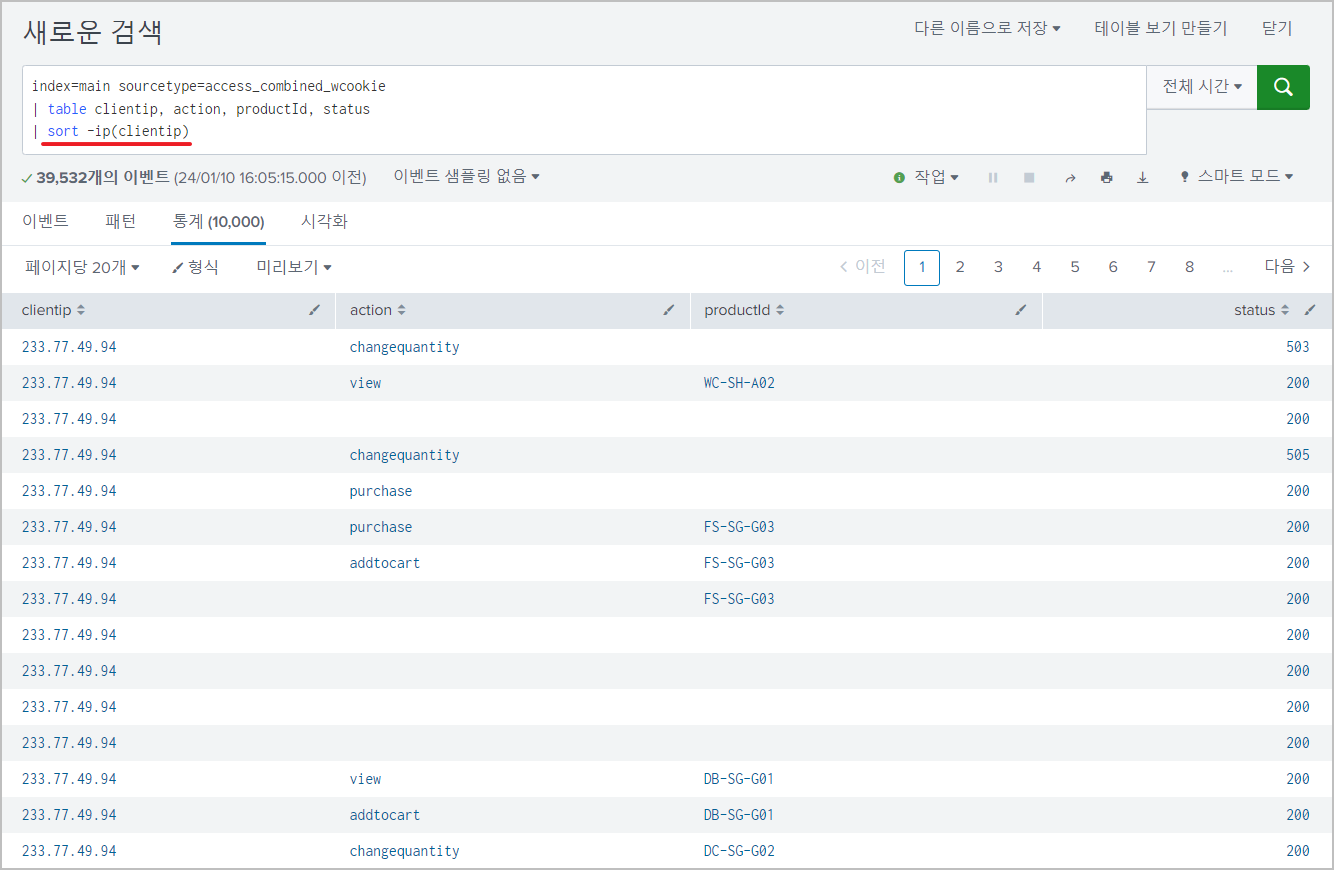
index=main sourcetype=access_combined_wcookie
| table clientip, action, productId, status
| sort -ip(clientip)
➞ * IP주소를 정렬할 경우 함수 ip() 또는 num( ) 사용
dedup
• 검색 결과에서 중복을 제거
dedup << 필드명1>>, << 필드명2>>
• 중복 제거는 지정한 필드를 기준으로 실행
• 두 개 이상의 필드에서 중복을 제거하려면 쉼표(,)로 구분
• 중복을 제거하면 해당 필드의 유일한 값을 기준으로 결과를 보여줌
• 중복을 제거하면 다른 필드의 값은 중복이 아닌데도 중복된 결과를 제거하면서 사라짐
• dedup은 상세 분석이 아니리 해당 필드에 존재하는 값을 확인하는 정도로 사용
index=main sourcetype=access_combined_wcookie status=404
index=main sourcetype=access_combined_wcookie status=404 | dedup host
stats
• 각종 통계 함수를 이용해서 데이터 계산
| stats [count|dc|sum|avg|list|values] by [필드명]

index=main sourcetype="access_combined_wcookie"
| stats sum(bytes), avg(bytes), max(bytes), median(bytes), min(bytes) by clientip
➞ 사용자마다 외부로 전송하는 바이트의 총합, 평균, 최대, 중간, 최소값을 검색
top
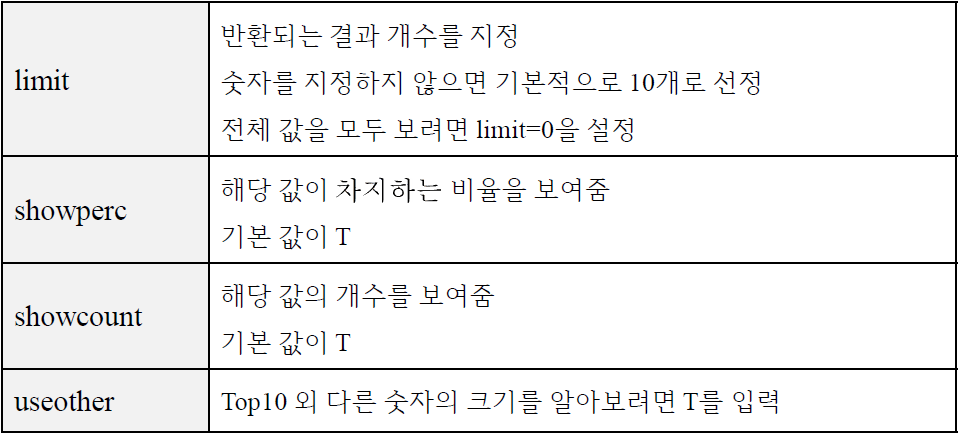
• 지정한 필드에서 가장 많이 나오는 값을 보여주는 명령어
| top limit=<숫자> [showperc=T/F] [showcount=T/F] [useother=T/F] 필드1, 필드2 by 필드
• 검색 결과를 파이프로 입력 받아서 계산 한 후에 결과를 반환
• showperc와 showcount의 기본값이 T이므로 지정하지 않더라고 비율과 개수를 보여줌
* | top useother=T clientip by method
method 필드를 기준으로 상위 10개의 clientip를 보여준다
useother=T에 의해 그 외(OTHER) 이벤트 개수를 보여준다

rare
• top과 반대의 결과인 빈도가 적은 값의 순서를 추출
| rare limit=<숫자> [showperc=T/F] [showcount=T/F] [useother=T/F] 필드1, 필드2 by 필드
* | rare useother=T clientip by method
- method 필드를 기준으로 하위 10개의 clientip과 그 외(OTHER) 이벤트 개수를 보여준다
차트 시각화
• 원본 로그 데이터로 차트를 그리는 것은 불가능하다
- 데이터를 차트로 만들려면 먼저 관련 데이터를 추출하고
- 시각화 원본 데이터를 통계 테이블로 변환한다
• 관련 명령어 : chart, timechart
timechart
• 시간에 따른 통계 테이블 생성
timechart span=[시간범위] 통계함수 by [필드명]
• 시간 필드가 X축, 실제데이타가 Y축에 표시되는 차트 시각화 형식으로 나타냄
• 시간에 따른 통계의 추세를 표시할 때 많이 사용
• Span : 시간 계산단위 설정
• Count : 전체 개수를 계산하는데 12시간 단위로 총 숫자를 구해서 보여줌
index=main sourcetype="access_combined_wcookie"
| timechart span=12h count(clientip) as "Access Count"
chart
• Timechart와 유사한 방식으로 동작
chart [통계함수] over X축 by [기준필드]
• Timechart는 span 옵션을 사용해서 시간 단위를 지정할 수 있지만 char명령어는 해당 옵션을 사용할 수 없음
index=main sourcetype="access_combined_wcookie"
| chart dc(clientip) as "Unique Count" over date_wday

비교 분석
명령어: eval, case, cidrmatch, if, like, match
eval
• 검사 결과 값의 변환, 검증을 수행하며 함수 실행 결과 값을 반환
| eval [반환값_저장변수] = 함수(인자1, 인자2..)
sourcetype=access_*
| eval status_code=if(status==200, "OK", "Error")
| table clientip status_code
index=httplog sourcetype=httplog
| eval list="mozilla"
| `ut_parse_extended(url,list)`
| table ut_netloc, ut_domain, ut_subdomain, ut_domain_without_tld, ut_tld
| dedup ut_netloc
case(X,”Y”,…)
• 여러 개의 조건을 검증할 때 사용
• 두 개의 인자가 한 그룹으로 동작
• 첫 번째 인자가 참인 경우 두 번째 인자의 내용이 반환, 세번째 인자가 참이면 네 번째 인자가 수행
index=httplog sourcetype=httplog
| eval description=case(error==404, "Not found", error==500, "internal Server Error")
| table clientip description
| eval quarter=case(date_month=="January", "1Q", date_month=="April", "2Q")
cidmatch(“X”,Y)
• 네트워크 범위 X에 IP주소 Y가 존재하는지 확인
• 반환 값은 참 또는 거짓이며 두 개의 인자가 사용
• 첫 번째 CIDR 형식의 네트워크 주소 범위, 두 번째는 검사를 위한 IP 주소가 입력
| eval local=cidrmatch("10.0.0.0/8", "10.10.0.100")
➞ IP 주소 10.10.0.100이 10.0.0.0/8 대역에 포함되면 true 아니면 false 반환
• cidrmatch 함수는 검색 필터로 사용할 수 있음
| where (cidrmatch("10.0.0.0/8", ip) OR
(cidrmatch("172.16.0.0/12", ip) OR
(cidrmatch("192.16.0.0/16", ip)
if(X,Y,Z)
• X가 참이면 Y를 실행하고, 거짓이면 Z 실행
* | eval ip1="10.10.0.100", ip2="100.10.0.100"
| eval network1=if(cidrmatch("10.10.0.0/24", ip1),"local", "external"),
network2=if(cidrmatch("10.10.0.0/24", ip2),"local", "external")
| table ip1, network1, ip2, network2
➞ IP 필드 값이 10.10.0.100이라면 10.10.0.0/24 네트워크에 포함되므로 network1 필드에 “local” 문자열 저장
➞ IP 필드 값이 100.10.0.100이라면 network2 필드에는 “external”이 할당된다
like(X,“Y”)
• Like 함수의 X필드에서 일부 문자열인 Y를 검색
• 첫 번째 인자는 대상 필드, 두 번째 인자는 정규 표현식의 탐색 패턴
• X필드에 Y값이 일부라도 있으면 참을 반환
• like 함수의 와일드 카드 문자열은 ‘%’
…| where like(field, "add%")
➞ field 변수가 addr로 시작하는지 검사
match(X,“Y”)
• Like 함수가 일부라도 맞는 값을 찾는다면 match함수는 함수명과 같이 정확한 일치여부를 비교
match(filename, "malicious.exe")
➞ Filename이 malicious.exe와 정확히 같으면 참, 그렇지 않으면 거짓을 반환
➞ 문자열 비교에 대소문자는 구분하지 않음
match(filename, "(.jpg|.gif|.png)$")
➞ $는 종결자로써 ‘$’ 앞의 문자로 단어가 끝난다는 의미
➞ ‘|’는 다중 선택을 의미
➞ Filename 필드 값이 .jpg, gif, .png로 종결($)하는지 검사
= 파일 확장자가 jpg, gif, png 여부 검사
match(method, "(GET|POST|-)")
➞ method가 GET, POST, 또는 “-” 인지 검사
NOT match(method, "(GET|POST|-)")
➞ method가 GET, POST, 또는 “-” 가 아닌 메소드들을 검사
index=httplog sourcetype=httplog
| where NOT match(method, "(GET|POST|-)")
| stats count(src) as src_count by method
| sort - src_count
➞
❶ method가 GET, POST, 또는 “-” 가 아닌 메소드들을 검사
❷ 검사된 메소드 별로 송신지 주소 개수를 세서 결과 반환
❸ 개수 Count(src)를 src_count에 저장
❹ 저장된 src_count 값을 기준으로 내림 차순 정렬
다중 문자열과 시간
명령어: split, mvindex, substr, round, urldecode, strftime, strptime, now
split(X,”Y”)
• X를 구분자 Y를 이용해서 분할해 다중값 형식으로 변환한다
• 구분자로 분리한 문자열은 여러 개의 토큰이 발생하므로 주로 mvindex()에서 사용
• 이벤트에서 특정 값을 추출할 때 사용

mvindex(X,Y,Z)
• 필드 X에 있는 Y 번째 값은 반환 (Z 생략가능)
• Y는 인덱스 번호 ( 0 : 첫 번째 값, -1 : 인덱스를 뒤에서 시작, -2 : 끝에서 두 번째)
• 세 번째 인자인 Z는 선택적으로 사용
- Z값을 지정하면 함수는 Y부터 Z까지의 값을 반환

substr(X,Y,Z)
• 세 번째 인자인 Z가 없다면 필드 X의 Y부터 시작해서 문자열 끝까지 반환
• Z가 주어지면 Y부터 Z개의 문자열을 반환
*| eval passwd_str="lightdm:x:107:117:Light Display M a n a g e r :/var/lib/lightdm:/bin/false"
| eval uid=mvindex(split(passwd_str,":"),0)
| eval subuid1=substr(uid,2)
| eval subuid2=substr(uid,2,4)
| table uid, subuid1, subuid2

round(X,Y)
• X를 Y 자리 수 기준으로 반올림
• 나누기 계산을 할 경우 소수점 자리가 급격히 늘어나는 것을 방지
urldecode(X)
• URL 인코딩이 있는 X를 디코딩해 반환
• 웹 주소에 한글이 사용되는 경우 대부분 URL인코딩이 되어 바로 확인이 힘듦
• 인코딩 문자열을 디코딩해서 한글이 있는 경우라도 바로 확인 할 수 있음
strftime(X,Y)
• 유닉스 타임 X를 지정한 Y형식으로 출력
• 주로 사용자가 읽기 편한 형식으로 변환할 때 사용
• 유닉스 타임(에포크 타임) 계산법은 1970년 1월 1일 0시를 기준으로 초를 계산
striptime(X,Y)
• strftime과 반대로 Y형식으로 된 X 시간 문자열을 입력받아서 유닉스 타임을 반환
'SK shieldus Rookies > 클라우드 기반 시스템 운영ㆍ구축 실무' 카테고리의 다른 글
| Splunk 실습 - HTTP Log 분석 (미완) (0) | 2024.01.11 |
|---|---|
| [SK shieldus Rookies 16기] Splunk 실습 - DNS Log 분석 (0) | 2024.01.11 |
| [SK shieldus Rookies 16기] Zeek 환경 구성 (0) | 2024.01.09 |
| Web 구조, HTTP 메시지 구조 (미완) (0) | 2024.01.09 |
| [SK shieldus Rookies 16기] HTTPS 구성 실습 (0) | 2024.01.08 |